

AWS Polly is great for adding speech to Raspberry Pi and similar, especially with the “neural” enhancement. Regular readers will know that for years I was a great fan of using Ivona speech on my Raspberry Pi. In Node-Red I used the free Ivona service to provide high quality speech in Node-Red at the heart of my home control setup. Ivona, good as it was, has been defunct now for some time. I’m now using Polly successfully on RPi4 and RPi5.
I’ve been asked what I use this for? Well, I do of course have Alexa and Google Home, both integrated to some extent into Node-Red and able to control things. However I never RELY on them as they rely completely on connectivity to the web. So does this – BUT If I need an alert or other phrase that I’ve used previously, of course the code works locally as there’s a local copy of the MP3 file on the RPi already so it then works without Internet. “Pete – time to take your pills” etc. comes to mind.
This post is derived from an original I wrote for Ivona in 2017 but completely overhauled for the (then new new) option in Polly as well as (optionally) including the voice-id (Amy is my favourite) in the input.
The Amazon Polly system is effectively a replacement for Ivona. The short, sharp answer is: Polly works, it is effectively free for casual use (<5 million characters a month or 1 million characters with the “neural” option). It is one of many Amazon AWS services… so CLI access usually begins “aws polly …”
Read on, as my simple Node-Red code caches speech recordings (.mp3 files) so that previously-used text does not require successive calls to Amazon servers. The code also allows for buffering of separate messages so they don’t overlap. In case you’re wondering, I could not see a decent AWS POLLY logo/icon on their website so I took the image above from a free-use, no-attribute site 🙂
So the Amazon “Polly” works via an AWS account. I have a free Amazon “developer” account and when I tried to add Polly – it said I didn’t have the right permissions – so – I added user pete to my account and made him part of the Polly group – and that didn’t work either – then I noted something about payment and realised I’d not put any payment details in – I did that – and all of a sudden the thing came to life. This has been running for 5-6 years now and I think they’ve charged me maybe 2 or 3 euros in all that time.
The way I use Polly is essentially simple – my code downloads an audio phrase as a .MP3 file given text input and saves it with a meaningful file name. Next time you want that exact phrase – the code checks to see if the file already exists – if so, it gets played locally, if not, the code gets a new file from AWS Polly and plays that. In a typical use-case that I for example might have, after a message is used once, it is kept in it’s own file for re-use and hence there’s no chance of incurring significant charges.
There are, no doubt, more elegant ways to do this than calling a command line from Node-Red – but this method works perfectly and as far as I know, the result is unique for Node-Red and Polly. Antonio Fragola (Mr Shark) and I have just got this to work on Node-Red in the latest PI OS (Bookworm 64 bit) in a Docker container on both RPi4 and RPi5 (minor changes to the Pi OS built-in amixer settings on RPi5 which also does not have a built-in 3.5mm jack audio out – so I’m using a USB audio dongle on the latter).
I’ll assume you have your aws credentials (ID and secret – simple – free) – don’t worry about location not being where you actually are.
Firstly – AWS Polly on Raspberry Pi4 using (32 bit) Pi OS Bullseye
To make sure AWS is working, use the command-line (CLI) code below – I’ve used this on RPi2 to 4 without any issues. As user pi, I created a folder called /home/pi/audio to store files… them after not using the speech for a while – I noticed this was failing in 2024 and so updated my Python and re-installed: you should now have Python 3.8 – it may work with later versions but I didn’t try that and installation will fail below Python v3.8
sudo pip install awscli
In the AWS initial setup, I set the region to us-west-1 for no other reason than initially not knowing any better – no matter as this gets overwritten in the code below where I use eu-west-2 which works fine with the NEURAL option. The output format you’d expect to enter might be MP3 but no – so I picked JSON for no good reason in the initial setup – again see the AWS POLLY example below as the Node-Red code overrides some initial settings.
Once AWS was installed and with my free AWS access key ID and secret handy, at the command line I used aws configure:
pi@ukpi:~ $ aws configure AWS Access Key ID [*********]: AWS Secret Access Key [**********]: Default region name [us-west-1]: Default output format [json]:
That done, I tried this test at the command line…
aws polly synthesize-speech --output-format mp3 --voice-id Amy --engine "neural" --region eu-west-2 --text "Hello my name is peter." /home/pi/audio/peter.mp3
The resulting file was an .MP3 sitting in my /home/pi/audio folder – this used the voice Amy (British female) to store a phrase into peter.mp3
MPG123 – I downloaded this in the normal manner…
sudo apt install mpg123
Amixer – well, on RPi 5, the amixer SEEMS to operate differently to RPi4 so I’ve had to change device (numid) to 6 and from percentages to an actual value where maximum is 400 matching my test inject of 100% – and non-linear down to apparently 0 for 0% etc. in the latter – but for now…
## max volume on RPi4 with internal audio amixer cset numid=1 -- 100%
Next step armed with my new recording and the RPi4 3.5mm jack connected to a powered speaker…
mpg123 /home/pi/audio/peter.mp3
Sorted – good for testing but as you’ll see the final solution is much better.
The Node-Red sub-flow below is about queuing messages, storing them with meaningful names, playing them back and making sure you don’t re-record a phrase you have already recorded. If you don’t like the default Amy – I’ve included the code to let you add another voice into your input (Brian for example). Important note: In this early part of the article I’m referring to Node-Red in native mode on Raspberry Pi all the way up to Pi OS Bookworm (Lite in my case) – NOT Node-Red in a Docker Container – that is a slightly different setup which I’ll cover further down.
If you want to add sound effects – just put .MP3 files in the audio folder and call them by filename. I have files like red-alert.mp3 and similar using Star Trek recordings. I also have my own .mp3 recordings using Polly.
The first part of my Node-Red code looks to see if the input payload has something in it and if so it pushes that onto a stack. The code then looks to see if any speech is already playing – if not and if there is something on the stack, it checks – if there is an .mp3 file it sends the file to the MP3 player. When it comes to the current request, If there is a matching .mp3, it immediately plays that file (assuming the queue is empty) otherwise the message is sent to aws Polly to create the file – which is downloaded then added to the output queue and then played back with a small delay depending on your broadband speed (for grabbing the .mp3 from the aws servers).
You clearly need your free Amazon account set up and Node-Red for this – you also need the free MPG123 player. Both Node-Red and MPG123 are included in my standard “The Script” – useful for earlier versions of Pi OS before Bookworm.
Here is the code I used pre-Bookworm…. the MPG123 exec node simply has mpg123 for the command and append payload ticked. The AWS exec node has aws for the command and append payload ticked. Both exec nodes have the output set to exec mode.
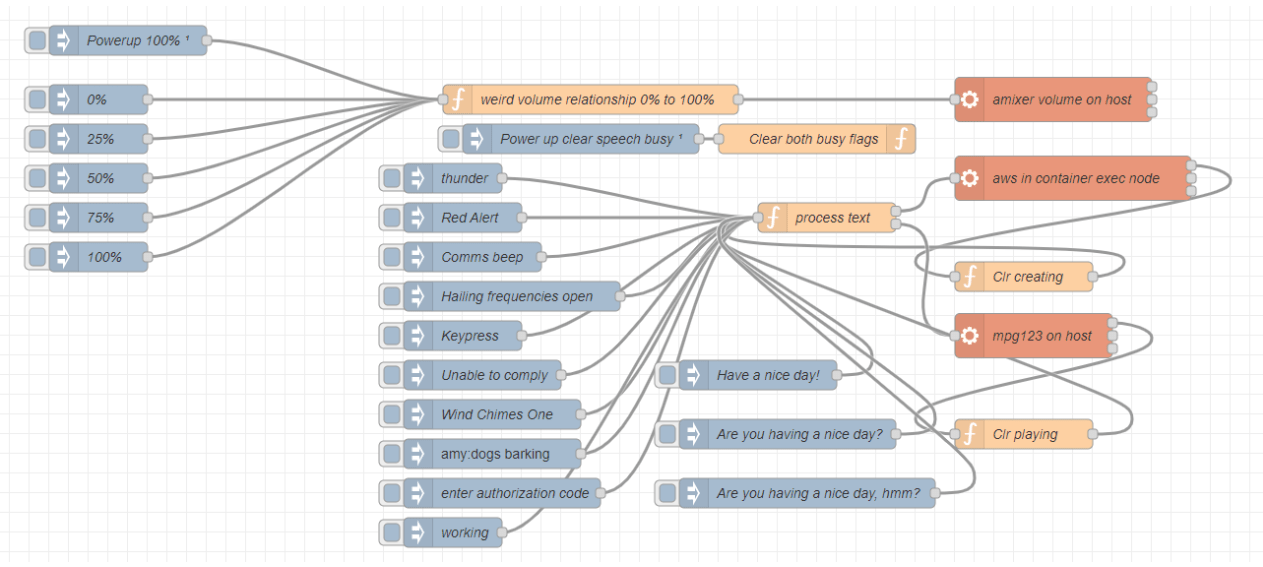
Here is the code for the flow below: Firstly the picture then the flow to include in Node-Red…
You can put the code in a Node-Red sub-flow (for ease of use) that can be used by simply injecting some text into the incoming payload. Here however I’ll just show it in a regular flow along with a use-once-at-power-up inject node to reset a couple of global variables so the code knows that Polly is not busy creating an .mp3 file and the MPG123 queuing code knows that no .mp3 file is currently playing. This code is for native installs and for Pi OS before Bookworm.
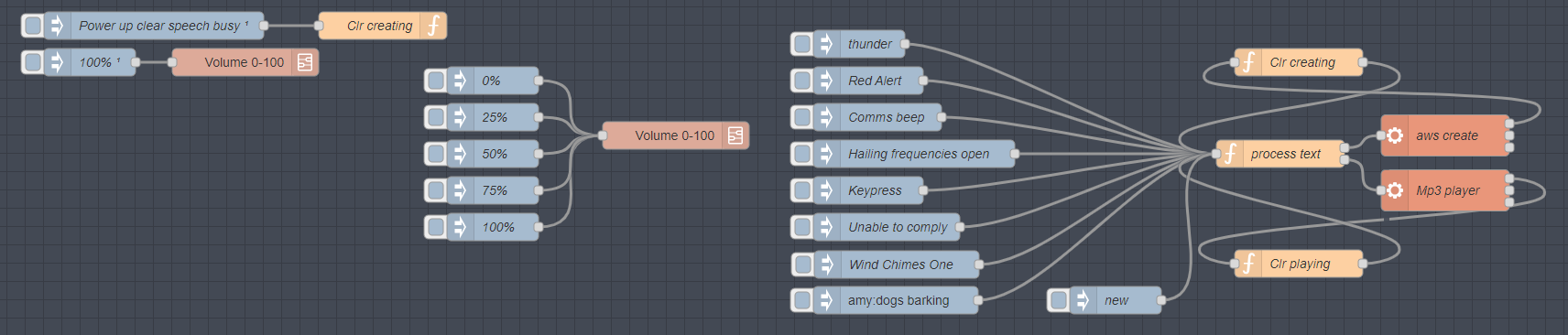
Rather large JSON FLOW file available here page-full – import into Node-Red minus the comments
There’s a piece missing in the above – the volume which I have as a NR sub-flow (just make a normal flow with INJECT nodes for testing).
My volume sub-flow relies on amixer:
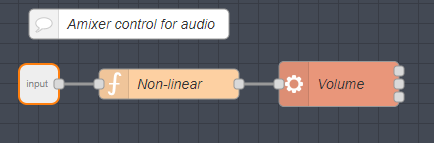
I feed a value 0-100 to a function (yellow box above) which then passes it’s output onto an EXEC function (orange). Sound values for amixer here 0-100 for 0% to 100% – the output sound levels are not linear hence a simple fix below:
var inv=msg.payload; if (inv<5) inv=0; else if (inv<10) inv=50; else if (inv<20) inv=67; else if (inv<30) inv=77; else if (inv<40) inv=84; else if (inv<50) inv=89; else if (inv<60) inv=93; else if (inv<70) inv=96; else if (inv<80) inv=98; else if (inv<90) inv=99; else inv=100; msg.payload="amixer cset numid=1 -- " + inv + "%"; return msg;
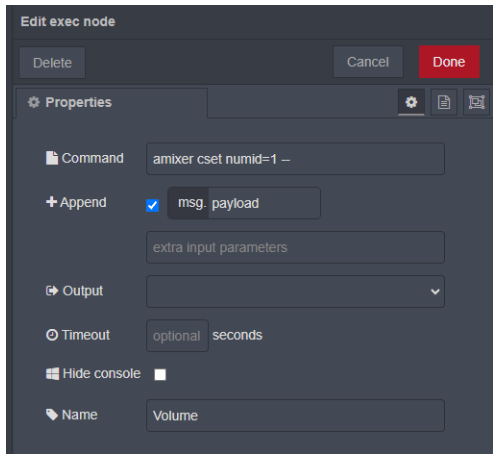
The content of the NR Exec node for volume control (again for Pi OS before Bookworm):
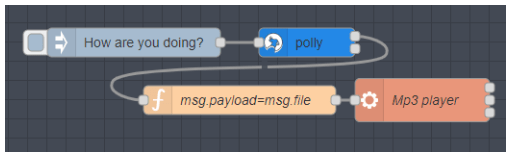
OK, HOLD THE PHONE – I just noticed a comment from 2017 referring to a node-red-node called node-red-contrib-polly-tts so this morning in 2024 I went off looking for it – and installed it. Sure enough it WORKS – BUT… simply feed text to it and your AWS credentials, add a simple function one-liner to convert msg.file to msg.payload and feed it to the MP3 Player exec node described earlier – for a second I was worried but when I compared my node set with this – result: Amy sound utterly BORED – I don’t know how to better describe it and I don’t THINK I can easily include audio files in the blog to demonstrate.
This POLY-TTS node referred to above definitely works and buffers messages but it also does NOT queue them “How are y.. how are you doing” for example with the first message truncated.. and the speech is very matter-of-fact synth – not a human asking a genuine question – so I’m not out of business yet 🙂
And Now, RPi4 and RPi5 Node-Red – Pi OS Bookworm – Docker version
Elswhere I’ve covered installing Antionio Fragola’s Docker setup on the RPi4 and 5 using P1 OS 64-bit Bookworm as there are charges in the setup which means my popular “The Script” setup script is no longer of practical use in the new environment – So Antonio took on the task of creating a Docker setup with all the utilities I normally use – Node-Red, Mosquitto, Grafana and much more – in a more device-independent manner. I’ve adopted this and Docker indeed does make for easy setup, backups and updates – but I’m sticking with my favourite SBC – Raspberry Pi mainly because of experience and rpi-clone – read about all of that in the related blog entries – but here I’m covering my speech setup on the Pi: amixer and mpg123 are running natively on the RPI4 as before I’m now including RPi5. Node-Red is now running in a Docker container and the aws-cli is also running in the Docker container – rather than copy information which could quickily become out of date, for installation of Node-Red and optionally much more. in order to then implement this audio setup on the RPi4/ RPi5 on which you will have set up Bookwork or Bookwork Lite, see Antonio’s GIT repository DockerIOT.
Firstly you might want a supply of .mp3 files – in this case mine (for testing – not my real collection) Referred to in here are a mix of pre-recorded .mp3 files – Star Trek alerts etc. and grabbed speech from aws Polly. See the video for details on the Node-Red code and example use… (slight reverb in the audio – but simple short videos never work as as they are supposed to).
Docker-specific json flow for Node-Red here – import into Node-Red minus the comments
This is important – assuming Docker is installed following Antonio’s method with /root/DockerIOT as the base – and Node-Red is already set up – you will then create the audio folder as below and you will store your files in there. To Node-Red, they will LOOK as if they are simply stored in /data/audio/ folder because Docker puts applications in their own effectively isolated environment.
mkdir -p /root/DockerIOT/nodered/data/audio chown -R 1000:1000 /root/DockerIOT/nodered/data
The key difference between aws (not Polly which is just one of many aws plugins) and the other containers is that aws runs as a command, it is called and after it completes (good or bad, not important now) its job, it exits and does not leave anything running in the background…
Once Node-Red is up and running in Docker, use Antonio’s alias at the command line in /root/DockerIOT/nodered and simply enter dstop (or the hard way: docker compose down) to stop Node-Red temporarily. Then go into the Node-Red folder – settings.js file and carefully add at the very beginning:
var fs = require("fs");
and at the end of settings.js, INSIDE the functionGlobalContext section add one line:
functionGlobalContext: {
fs:require('fs'),
},
That applies to both the RPi4 and RPi5 versions.
Note: Antonio recommends factorizing that “/root/DockerIOT/nodered” which is used a couple of times in that flow, in a variable, let’s say, “host_path_prefix”, to clarify further that should be added ONLY for commands running on the host (via the ssh exec node) that need the full path instead of just the internal subpaths “/data/…” which instead should be used for nodes accessing stuff INSIDE the container itself… BOTH point to the SAME data (thanks to the volume mounting the local folder to the container one) but should be managed differently: commands running on the host via ssh and addressing HOST should use full paths INCLUDING that “prefix” one, while commands addressing CONTAINER mounted paths and because of this with normal nodes, and not exec and ssh, won’t need that prefix.
I’ve been playing at root command level on the RPi5:
aws polly synthesize-speech --output-format mp3 --engine 'neural' --voice-id Amy --region eu-west-2 --text "Hmmm.. that's very nice!" /root/DockerIOT/nodered/data/audio/nonsense.mp3 mpg123 /root/DockerIOT/nodered/data/audio/nonsense.mp3
That’s working – but amixer was being awkward:
amixer cset numid=1 -- 100%
The latter was failing… HOWEVER, the MP3 file plays and ALSAMIXER (pre-installed – NOT command line – some kind of CLI graphical interface) lets me set the volume higher than I’d managed so far on RPi5.

Hitting F6 says the audio device is default 0: USB Audio Device – yet amixer on RPi5 says that device 0 is an invalid device. Amixer on RPi5 however DOES seem happy with numid=6
So, by experimenting, I discovered that on the RPi5 both in Docker and in native mode, I had to rethink the volume control – and by experiment, with value 400 (not percent) as full and value 0 as apparently 0, I came up with a non-linear solution for my volume control – here’s the “entire “non linear” function revamped for RPi5 only. Feel free to play with those intermediate values.
var inv=msg.payload; if (inv==0) inv=0; else if (inv<=25) inv=10; else if (inv<=50) inv=20; else if (inv<=75) inv=25; else if (inv<=100) inv=400; msg.payload="amixer cset numid=6 -- " + inv; return msg;
And in the end…
With apologies to those who have commented on the AWS Polly article – now hidden – I tried to introduce a better WordPress plug-in for showing large code sections (color-coding, summary views) but it ended up killing the original version of this blog entry – if you see any new comments in here – be very careful if copying code from them – WordPress has a habit of mangling quotes and other special characters. Given the above recent experience I’m wary of experimenting with other (for me) untested plug-ins which might improve the native comments code or indeed improve on the existing code blocks.
Antonio’s last comment before I lost the original:
“ssh from container to host is now MUCH faster, I enabled re-using ssh connections and other things
Whoever starts from scratch now has a new setup script that will take care of EVERYTHING (creates all folders, sets up permissions, and generate ssh keypairs with automatic config of the host), check the updated readme: https://github.com/fragolinux/DockerIOT/tree/main/nodered
For those who already have their systems running, i created this gist which will explain everything you need to get this, all those parameters are now defined in a ssh config file, automatically used: https://gist.github.com/fragolinux/4cee96518cd4926cca404eba36411dd3
Check the screenshot, the exec node MUST be modified as in this image… AS IT IS, do not touch the command line, it’s CORRECT, just modify the second text box, as usual…
1st ssh will be slow as before, but once run, next ones are way faster (on my system, 2.45s 1st, 0.056s next ones…)
Connections are recycled after 10 minutes, so after this time, again 1st one will be slow… if you want more, change the value in the ssh/config file, or add an inject node that just makes an “ls > /dev/null” on the host via exec ssh every few minutes, to have an always fresh connection already setup and ready to be used.
Of course if you check the APPEND and put in your own payload, REMOVE the text from that textbox which is meant to directly provide a command to be executed”